Bab ini akan membahas teori-teori yang berhubungan dengan topik yang dibahas pada penelitian ini. Topik-topik ini terdiri dari State of The Art, Citra Digital, Augmentasi Data, Convolutional Neural Network, Connectionist Temporal Classification, Adam Optimizer, Bayesian Optimization, dan Metode Evaluasi.
State of The Art
Work in Progress
| Penelitian | Deteksi | Rekognisi | Data | Metode | Hasil (Akurasi) |
|---|---|---|---|---|---|
| (Pan et al., 2023) | True | True | Chinese City Parking Dataset (CCPD) | YOLOv7 & LPRNet (Segmentation Free) | Akurasi rekognisi 96.1% |
| (Shan Luo & Jihong Liu, 2022) | True | True | CCPD | YOLOv5m & LPRNet (Segmentation Free) | Akurasi rekognisi 99.49% |
| (Shi & Zhao, 2023) | True | True | CCPD | YOLOv5 & GRU (Segmentation Free) | Akurasi rekognisi 97.9% |
| (Shafi et al., 2022) | True | True | Proprietary Pakistani Dataset | SSD300 (Character Segmentation) | Akurasi rekognisi 99.18% |
| (Tung et al., 2021) | True | True | AOLP, Private Vehicle License Plate | Dual-stage License Plate Recognition, MobileNets, RetinaFace, CRNN (Segmentation Free) | Rata-rata akurasi deteksi dan rekognisi 97.70% |
| (Wang et al., 2022) | False | True | Applications-oriented License Plate (AOLP) Dataset, UFPR Dataset, CCPD | Depthwise Separable Convolution Networks (Segmentation Free) | Akurasi rekognisi 99.18% |
Citra Digital
Citra atau gambar digital merupakan bentuk representasi visual yang dihasilkan dari proses konversi objek fisik atau pemandangan menjadi data yang dapat diproses oleh perangkat komputer. Citra ini terdiri dari elemen-elemen kecil yang dikenal sebagai piksel, di mana setiap piksel disusun dalam baris dan kolom membentuk grid dua dimensi (Dijaya & Setiawan, 2023).

Citra dapat didefinisikan sebagai fungsi dua dimensi, f(x, y), di mana x dan y adalah koordinat spasial yang merepresentasikan lokasi piksel dalam bidang gambar. Amplitudo dari fungsi f pada setiap pasangan koordinat (x, y) disebut intensitas atau tingkat keabuan dari citra pada titik tersebut (Gonzalez & Woods, 2017). Setiap titik dalam gambar memiliki nilai intensitas yang menunjukkan seberapa terang atau gelap piksel tersebut. Nilai intensitas ini sangat penting dalam analisis citra, karena memberikan informasi mengenai detail visual yang ada dalam gambar, baik itu berupa tekstur, tepi, maupun objek yang terkandung di dalamnya.
Augmentasi Data
Augmentasi data berperan penting dalam meningkatkan variasi dataset gambar yang digunakan dalam pelatihan model (Sanjaya & Ayub, 2020). Teknik ini dilakukan dengan mengubah beberapa aspek geometris dari gambar, seperti rotasi, translasi, skala, dan distorsi perspektif. Manipulasi dimensi gambar melalui augmentasi bertujuan untuk menghasilkan gambar baru yang menyerupai kondisi nyata yang mungkin dihadapi oleh model. Dengan demikian, model dapat lebih siap dalam menghadapi gambar dengan variasi yang lebih luas, termasuk gambar yang diambil dalam kondisi yang berbeda-beda.
Tujuan utama dari augmentasi data adalah untuk meningkatkan ketahanan dan akurasi model machine learning (Mumuni & Mumuni, 2022). Dengan menambah variasi dalam data, augmentasi membantu model untuk lebih tahan terhadap perubahan atau noise yang ada di data uji, sehingga performa model menjadi lebih stabil. Selain itu, augmentasi memungkinkan model untuk bekerja dengan baik meskipun hanya dilatih pada data yang relatif kecil atau kurang representatif. Hal ini sangat penting dalam skenario di mana pengumpulan data berkualitas tinggi dalam jumlah besar sulit dilakukan, sehingga augmentasi data menjadi solusi efektif untuk mengatasi keterbatasan tersebut.
Beberapa contoh augmentasi yang sering digunakan pada citra digital seperti rotasi, penskalaan, translasi, shear, dan perubahan perspektif. Gambar x menunjukkan hasil dari augmentasi yang dilakukan pada sebuah gambar.
Convolutional Neural Network
Deep learning (DL) adalah sekumpulan algoritma dalam machine learning yang menggunakan banyak lapisan, di mana setiap lapisan merepresentasikan tingkat abstraksi yang berbeda-beda. Struktur dari algoritma ini terdiri dari lapisan input, lapisan output, dan beberapa lapisan tersembunyi (hidden layers) di antaranya. Setiap lapisan tersembunyi bertugas mengolah informasi dari lapisan sebelumnya, memperdalam pemahaman model terhadap data.
Teknologi deep learning telah diterapkan dalam berbagai bidang seperti sintesis suara, pengolahan citra, pengenalan tulisan tangan, deteksi objek, analitik prediksi, dan pengambilan keputusan (Chahal & Gulia, 2019). Dengan lapisan-lapisan yang kompleks ini, deep learning mampu menangani tugas-tugas yang membutuhkan pemahaman mendalam terhadap data yang sangat besar dan bervariasi.
Convolutional Neural Network (CNN) adalah pengembangan dari Multilayer Perceptron (MLP) yang didesain untuk mengolah data dua dimensi. CNN termasuk dalam jenis Deep Neural Network karena kedalaman jaringan yang tinggi dan banyak diaplikasikan pada data citra. Pada kasus klasifikasi citra, MLP kurang sesuai untuk digunakan karena tidak menyimpan informasi spasial dari data citra dan menganggap setiap piksel adalah fitur yang independen sehingga menghasilkan hasil yang kurang baik (Rifki et al., 2021).
Convolution Layer
Convolution (Konvolusi) adalah operasi matematika pada dua fungsi untuk menghasilkan fungsi ketiga yang mengekspresikan bagaimana bentuk satu dimodifikasi oleh yang lain. Tujuan konvolusi pada data citra adalah untuk mengekstraksi fitur dari citra input. Konvolusi akan menghasilkan transformasi linear dari data input sesuai informasi spasial pada data (Rifki et al., 2021).

Konvolusi merupakan operasi dasar dalam banyak bidang matematika dan ilmu komputer, terutama dalam pengolahan sinyal dan citra. Dalam konteks CNN, konvolusi digunakan untuk memodifikasi dan menggabungkan dua fungsi, di mana satu fungsi merepresentasikan input, dan fungsi lainnya, yang sering disebut kernel atau filter, bertugas untuk memproses dan mengekstraksi pola dari input tersebut (Andika et al., 2019). Hasil dari operasi ini adalah fungsi baru yang merepresentasikan bagaimana pola dari input terpengaruh oleh filter yang digunakan. Istilah “konvolusi” tidak hanya merujuk pada hasil akhirnya, tetapi juga proses perhitungan yang dilakukan untuk mendapatkan hasil tersebut.
Dalam konteks pengolahan citra digital, konvolusi memiliki peran penting untuk mengekstraksi fitur-fitur penting dari citra input, seperti tepi, sudut, dan tekstur. Proses ini dilakukan dengan menggeser filter kecil di atas citra untuk menghasilkan representasi spasial baru yang mempertahankan karakteristik penting dari gambar asli. Hasil dari konvolusi ini adalah transformasi linear dari input citra yang mempertimbangkan keterkaitan spasial antara piksel-piksel yang berdekatan. Melalui konvolusi, model dapat mengenali pola-pola spesifik pada gambar yang menjadi dasar bagi model untuk memahami konten visual secara lebih mendalam.
Pooling Layer
Pooling Layer merupakan lapisan yang menggunakan fungsi dengan feature map sebagai masukan dan mengolahnya dengan berbagai macam operasi statistik berdasarkan nilai piksel terdekat. (Rifki et al., 2021). Pooling Layer berfungsi untuk mengurangi dimensi dari feature map yang dihasilkan oleh lapisan konvolusi. Pengolahan ini dilakukan dengan menggunakan fungsi pooling seperti max pooling atau average pooling, yang mengambil nilai maksimal atau rata-rata dari kumpulan piksel terdekat. Dengan demikian, pooling layer dapat menyaring informasi yang paling penting dari citra tanpa harus menyimpan semua detail piksel. Dalam praktiknya, pooling layer biasanya disisipkan secara berkala setelah beberapa lapisan konvolusi untuk mengurangi ukuran data dan mempercepat proses komputasi tanpa mengorbankan keakuratan model.
Selain mengurangi ukuran citra, pooling layer juga mempertahankan informasi penting dari fitur-fitur yang telah diekstraksi oleh lapisan sebelumnya. Dengan mengurangi dimensi gambar, lapisan ini membantu mempercepat proses pelatihan model sekaligus mengurangi risiko overfitting. Meskipun resolusi citra berkurang, fitur yang paling signifikan, seperti tepi dan pola tekstur, tetap dipertahankan. Hal ini memungkinkan model untuk terus belajar dari data yang lebih kecil dan lebih terstruktur, sehingga meningkatkan efisiensi dan akurasi dalam mengenali objek dalam gambar.

Batch Normalization
Batch normalization (BN) adalah teknik normalisasi yang diterapkan pada lapisan jaringan saraf untuk mempercepat proses pelatihan dan meningkatkan stabilitas model. Teknik ini bekerja dengan menormalkan output dari setiap lapisan sebelum diteruskan ke lapisan berikutnya, menggunakan rata-rata dan varians dari mini-batch data yang sedang diproses. Proses ini dilakukan dengan mengurangi rata-rata aktivasi dan membaginya dengan simpangan baku aktivasi tersebut, kemudian disesuaikan menggunakan parameter yang dipelajari (Ioffe & Szegedy, 2015). Penggunaan BN dalam model DL dapat meningkatkan kinerja model dalam melakukan generalisasi dan mengurangi waktu pelatihan model.
Persamaan tersebut menuliskan dan masing-masing sebagai input dan output dari layer BN yang berupa tensor empat dimensi. Empat dimensi tersebut mencakup batch , channel , dan dua dimensi spasial . Aktivasi input akan dikurangi aktivasi rata-rata oleh lapisan BN. Kemudian, aktivasi yang telah dikurangi dinormalisasi dengan cara membagi dengan akar dari simpangan baku yang ditambah untuk kestabilan numerik. Setelah normalisasi, dilakukan transformasi linier per channel yang ditentukan oleh parameter dan . Kedua parameter ini dipelajari selama proses pelatihan. (Bjorck et al., 2018)
Spatial Transformer Network
Spatial Transformer Network (STN) adalah jaringan yang mempelajari suatu fungsi untuk menghasilkan parameter dari transformasi affine, yang bertujuan untuk memodifikasi citra input agar lebih mudah diklasifikasikan (Nies et al., 2022). Jaringan ini dipelajari melalui neural network yang secara otomatis mengestimasi transformasi yang diperlukan, seperti rotasi, skala, dan translasi, sehingga objek dalam citra lebih mudah diidentifikasi oleh model. STN memungkinkan jaringan untuk melakukan penyelarasan atau normalisasi input sebelum diolah lebih lanjut, yang membantu meningkatkan akurasi klasifikasi. Modul Spatial Transformer memiliki tiga bagian, yaitu localization network (LocNet), grid generator, dan parameterized grid sampler.
LocNet menerima fitur map dengan lebar , tinggi , channel dan menghasilkan output . Output merupakan hasil dari yang berfungsi sebagai parameter transformasi yang akan diaplikasikan pada fitur input. Fungsi LocNet dapat berupa apa saja, seperti sebuah fully-connected network atau convolutional network, namun harus memiliki layer regresi terakhir untuk menghasilkan parameter transformasi (Jaderberg et al., 2016).
Setelah transformasi dihasilkan, dilakukan proses grid generation di mana grid koordinat output dihitung dari koordinat input berdasarkan transformasi yang telah dipelajari. Contoh umum adalah transformasi affine, yang menggunakan enam parameter dalam bentuk matriks ..
Di sini, adalah koordinat output setelah transformasi, sementara merupakan koordinat input asli. Setelah grid baru dihasilkan, dilakukan proses sampling untuk memetakan koordinat baru ke gambar asli. Karena grid yang dihasilkan biasanya tidak berkorespondensi langsung dengan piksel, digunakan metode interpolasi bilinear untuk menghitung nilai di koordinat baru sebagai hasil interpolasi linier dari piksel terdekat di feature map input.
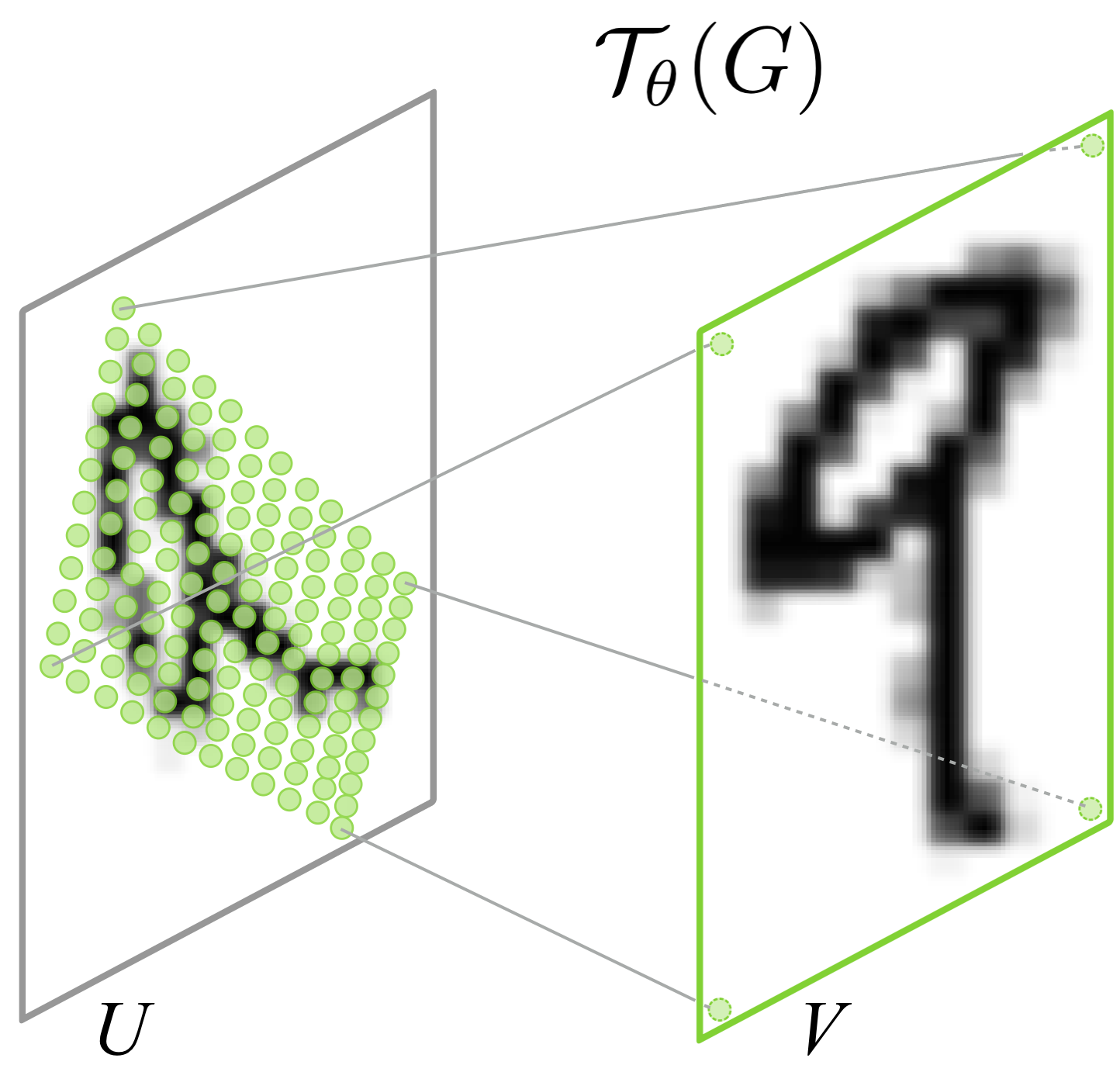
Proses pembelajaran dalam STN dilakukan dengan meminimalkan classification loss, yaitu selisih antara prediksi model dan label sebenarnya. Jaringan ini dilatih untuk mencari transformasi optimal yang tidak hanya mempermudah proses pengenalan pola, tetapi juga mempertahankan informasi penting dari citra asli. Dengan adanya STN, model dapat menangani citra yang memiliki berbagai distorsi geometris, seperti citra yang miring atau tidak sejajar, sehingga kinerja klasifikasi tetap stabil di berbagai kondisi input.
Arsitektur LPRNet
Work in Progress
LPRNet (Zherzdev & Gruzdev, 2018) menggabungkan Spatial Transformer Layer, CNN ringan dan sederhana sebagai backbone, dan modul klasifikasi per-karakter untuk menghasilkan probabilitas karakter yang selanjutnya bisa didekode menjadi urutan karakter. Walaupun banyak jaringan klasifikasi yang tangguh seperti VGG, ResNet, dan GoogLeNet, arsitektur CNN yang ringan dipilih karena merupakan opsi terbaik untuk membuat jaringan yang cepat dan ringan.
Pertama, Spatial Transformer Layer melakukan praproses terhadap citra input. Langkah ini opsional, namun memungkinkan model untuk mengenali bagaimana mentransformasi citra yang beragam untuk mengenali karakteristik dengan lebih baik. Arsitektur LocNet yang digunakan untuk mencari parameter transformasi yang optimal ditunjukkan pada Tabel x. Citra output dari STN tetap berukuran yang sama seperti citra input.
Insert tabel LocNet
Arsitektur jaringan backbone menerima citra RGB sebagai input dan menghitung fitur-fitur yang terdistribusi secara spasial. Konvolusi lebar dengan kernel memanfaatkan konteks fitur lokal. Output dari backbone dapat diinterpretasikan sebagai sebuah urutan dari probabilitas karakter yang panjangnya sesuai dengan lebar dari citra input.
Untuk meningkatkan performa, fitur pra-dekoder ditambahkan dengan global context embedding. Fitur ini dihitung menggunakan sebuah fully-connected layer pada output-output dari beberapa layer backbone, disusun sesuai dengan ukuran yang diinginkan, dan dirangkai dengan output dari backbone. Penambahan konvolusi diterapkan untuk menyesuaikan kedalaman fitur dengan banyaknya kelas karakter. Gambar x menunjukkan keseluruhan arsitektur LPRNet.

Connectionist Temporal Classification
Connectionist Temporal Classification (CTC) adalah kriteria pelatihan yang dirancang untuk masalah pelabelan urutan, khususnya ketika penyelarasan antara input dan label target tidak diketahui secara eksplisit. Metode ini sangat berguna dalam kasus di mana panjang input dan output tidak sama, seperti dalam pengenalan suara atau teks dari gambar (Chao et al., 2020). CTC memungkinkan model untuk memprediksi urutan keluaran tanpa perlu mengetahui secara pasti di mana setiap elemen label target muncul dalam urutan input. Ini dicapai dengan menghasilkan distribusi probabilitas pada setiap time step dan memungkinkan jaringan saraf untuk mencari urutan yang paling mungkin cocok dengan output target.

Dalam praktiknya, CTC sering digunakan pada masalah yang melibatkan pengenalan urutan, seperti pengenalan suara otomatis, pengenalan teks pada citra, dan pemrosesan video. Salah satu keunggulan utama dari CTC adalah kemampuannya untuk menangani situasi di mana elemen-elemen urutan mungkin tumpang tindih atau muncul dalam interval waktu yang tidak tetap. CTC juga dapat mengabaikan elemen-elemen yang tidak relevan dalam input dengan menggunakan label khusus yang disebut “blank” atau biasa dilambangkan yang membantu model memfokuskan pada elemen-elemen penting dari urutan.
Adam Optimizer
Work in Progress
Necessary?
Pelajarin lagi apakah ini dibutuhkan? Pelajarin juga perhitungannya!
Adam (Adaptive Moment Estimation) adalah algoritma optimisasi yang banyak digunakan dalam pelatihan jaringan saraf dalam. Adam menggabungkan keuntungan dari dua metode optimisasi populer, yaitu Momentum dan RMSProp (Kingma & Ba, 2017). Algoritma ini dirancang untuk mempercepat proses konvergensi dengan memanfaatkan estimasi momen pertama (rata-rata) dan momen kedua (variansi) dari gradien.
Adam bekerja dengan memperbarui parameter model berdasarkan dua estimasi momen gradien. Estimasi pertama, , merupakan rata-rata tertimbang dari gradien yang diperoleh dari iterasi sebelumnya, mirip dengan pendekatan Momentum. Estimasi kedua, , merupakan rata-rata tertimbang dari kuadrat gradien, seperti yang dilakukan oleh RMSProp. Pembaruan parameter dilakukan dengan mempertimbangkan kedua momen ini, yang kemudian disesuaikan dengan bias untuk meningkatkan stabilitas.
Rumus pembaruan parameter Adam adalah sebagai berikut:
Pada persamaan di atas, adalah gradien pada iterasi , adalah laju pembelajaran (learning rate), dan adalah faktor peluruhan eksponensial untuk momen pertama dan kedua, dan adalah konstanta kecil untuk menghindari pembagian dengan nol.
Adam memiliki beberapa kelebihan dibandingkan metode optimisasi lainnya. Algoritma ini secara otomatis menyesuaikan laju pembelajaran untuk setiap parameter, sehingga lebih efisien dalam menangani masalah dengan gradien yang jarang (sparse gradients). Selain itu, Adam sangat efektif dalam menangani data dengan dimensi yang tinggi dan stabil terhadap fluktuasi gradien, sehingga banyak digunakan dalam berbagai aplikasi deep learning. Penelitian menunjukkan bahwa Adam memberikan hasil yang baik dalam berbagai tugas pembelajaran mendalam, termasuk pengenalan citra, pemrosesan bahasa alami, dan reinforcement learning.
Bayesian Optimization
Work in Progress
Necessary?
Metode Evaluasi
Dalam penelitian ini, dua metode evaluasi utama digunakan untuk menilai kinerja model dalam mengenali karakter pada plat nomor kendaraan. Metode pertama adalah Letter Number Recognition Rate (RLN), yang secara spesifik mengukur seberapa baik sistem mengenali huruf dan angka pada plat nomor. Metode kedua adalah Character Error Rate (CER), yang mengevaluasi akurasi pengenalan karakter dengan memperhitungkan jumlah kesalahan dalam transkripsi. Kedua metode ini digunakan secara bersamaan untuk memberikan gambaran yang lebih komprehensif terkait performa model dalam tugas pengenalan plat nomor.
Letter Number Recognition Rate
Letter Number Recognition Rate (RLN) adalah metode evaluasi yang dicanangkan oleh (Youting et al., 2018). Uji ini dirancang untuk mengukur performa, dan tidak memperhatikan masalah implementasi waktu seperti kecepatan implementasi. Rumus berikut digunakan untuk mengukur performa dalam mengenali karakter plat nomor.
Persamaan tersebut menuliskan sebagai jumlah huruf dan angka yang dapat dikenali secara akurat oleh sistem. dibagi dengan hasil perkalian dan yang masing-masing merupakan jumlah gambar lokasi sistem dengan wilayah plat nomor dan jumlah huruf dan angka pada plat nomor.
Character Error Rate
Character Error Rate (CER) adalah metrik yang digunakan untuk mengukur akurasi dari sebuah model pengenalan teks. CER merepresentasikan persentase karakter yang ditranskripsi secara salah. Metrik ini telah diadaptasi untuk berbagai tugas lain, seperti optical-character recognition (OCR) dan LPR, di mana penilaian akurasi pada tingkat karakter sangat penting. Salah satu penelitian yang dilakukan oleh (Dong et al., 2017) juga menggunakan CER sebagai metrik utama dalam mengevaluasi performa sistem mereka. Dalam kasus LPR, CER sangat berguna karena sistem harus mengenali karakter individu pada plat, dan evaluasi model pada tingkat yang lebih rinci memastikan bahwa bahkan kesalahan kecil dapat diperhitungkan dengan benar.
Rumus berikut digunakan untuk menghitung CER:
Pada persamaan tersebut, mewakili jumlah karakter yang salah dikenali (substitutions), merupakan jumlah karakter yang tidak dikenali (deletions), dan adalah jumlah karakter tambahan yang keliru dikenali oleh sistem (insertions). merupakan jumlah total karakter pada teks referensi.